Коллектив ученых из МФТИ и Института искусственного интеллекта AIRI разработал новую систему, которая позволяет колесным роботам самостоятельно перемещаться между этажами зданий, используя обычный пассажирский лифт. Их подход, получивший название LaMDEN, объединяет построение подробной трехмерной карты окружения и возможности больших языковых моделей для планирования сложных действий.
Эта разработка — важный шаг на пути к созданию по-настоящему автономных сервисных роботов, способных эффективно работать в сложной человеческой среде, от офисов и больниц до жилых комплексов. Работа опубликована в журнале Optical Memory and Neural Networks (результаты работы были представлены на конференции 2025 International Joint Conference on Neural Networks (IJCNN) и опубликованы в ее официальных трудах издательством IEEE). Код проекта и созданный набор данных находятся в открытом доступе для всего научного сообщества.

Две среды для тестирования. В левой части находится только лифт, а в правой — лифт и лестница. Источник: IJCNN Proceedings
Современные мобильные роботы уже способны выполнять множество полезных задач, однако их операционный радиус часто ограничен одним этажом. Лестницы для большинства колесных платформ остаются непреодолимым препятствием. Единственный способ для таких машин обрести свободу передвижения в многоэтажном здании — научиться взаимодействовать с лифтами.
Эта задача, тривиальная для человека, для искусственного интеллекта представляет собой сложный вызов. Робот должен не просто найти лифт, но и понять, как им пользоваться: распознать и нажать нужные кнопки, дождаться открытия дверей, оценить, свободна ли кабина, войти в нее, выбрать этаж назначения и, наконец, выйти. Решение задачи требует от машины не только точной навигации, но и семантического понимания окружающего мира и умения планировать многошаговые действия.
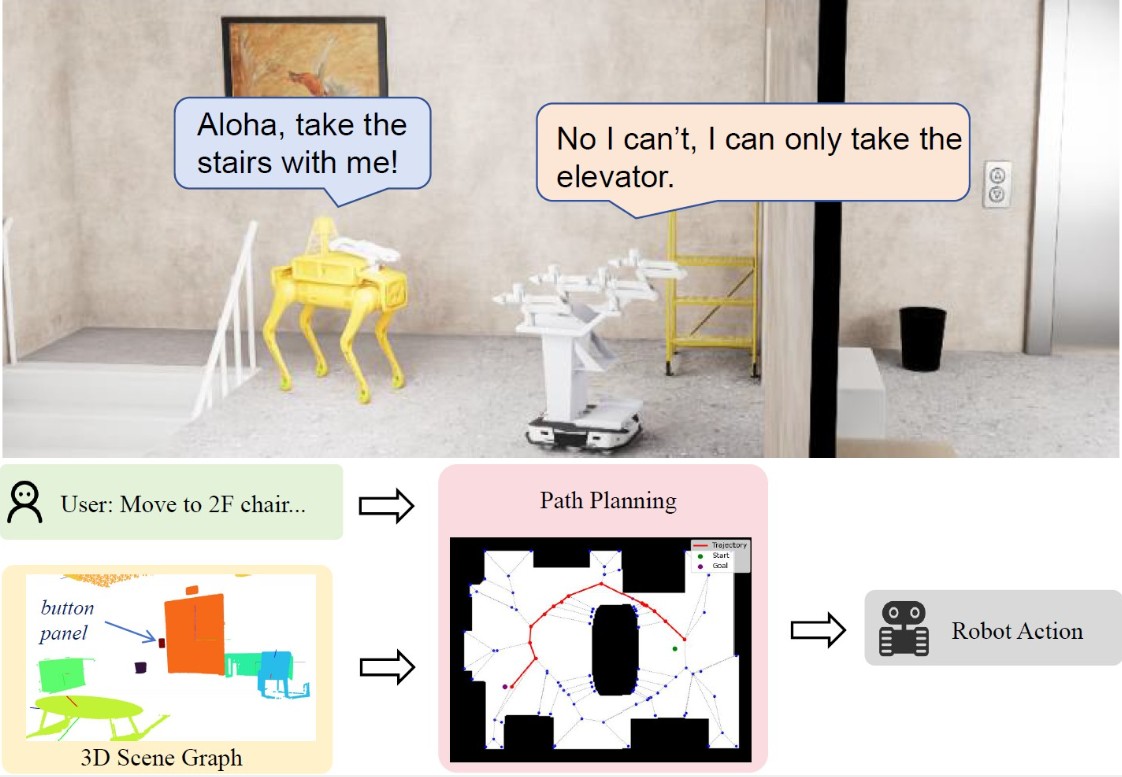
Рисунок 1. Визуализация работы системы LaMDEN. Получив от человека общую команду, робот сначала обращается к трехмерной карте-графу для понимания окружения, затем с помощью большой языковой модели планирует последовательность действий (например, найти и нажать кнопку лифта) и выполняет их в физическом мире. Источник: IJCNN Proceedings
Подходы в робототехнике и наборы данных для обучения роботов часто упускали из виду именно интерактивный аспект использования лифтов, концентрируясь на навигации по лестницам, доступной лишь шагающим механизмам. Чтобы восполнить этот пробел, исследователи из МФТИ и AIRI поставили перед собой цель создать комплексную систему, которая наделила бы робота всеми необходимыми навыками для самостоятельного использования лифта.
Ученые создали два проекта — LaMDEN и ElevNAV. Первый содержит в себе универсальное решение для перемещения роботов-манипуляторов между этажами, а второй используется при создании набора данных, описывающего лифтовые зоны.
В основе предложенной ими разработки LaMDEN лежат два ключевых компонента. Сначала робот, используя данные с RGB-D камеры, которая воспринимает не только цвет, но и глубину пространства, строит так называемый граф трехмерной сцены. Это не просто геометрическая карта, а богатая семантическая модель мира, своего рода «социальная сеть» для объектов.
В этом графе узлами являются сами объекты — «лифт», «дверь», «панель с кнопками», а ребрами — связи между ними, описывающие их пространственное и логическое взаиморасположение. Такая карта дает роботу глубокое контекстуальное понимание того, где он находится и что его окружает.
Когда граф сцены построен, в дело вступает второй компонент — большая языковая модель (LLM), схожая с технологией, лежащей в основе ChatGPT. Она выступает в роли «мозга», или внутреннего планировщика. Получив от человека высокоуровневую команду, например: «отправляйся к столу на третьем этаже», языковая модель декомпозирует эту сложную цель в последовательность простых, элементарных действий, понятных роботу.
Этот процесс похож на то, как человек проговаривает про себя план: сначала нужно подойти к панели вызова лифта, нажать кнопку «вверх», дождаться, войти, нажать кнопку с цифрой 3. Языковая модель генерирует для робота именно такой пошаговый план, состоящий из «примитивов действия»: «двигаться к объекту», «нажать кнопку», «войти» или «выйти».
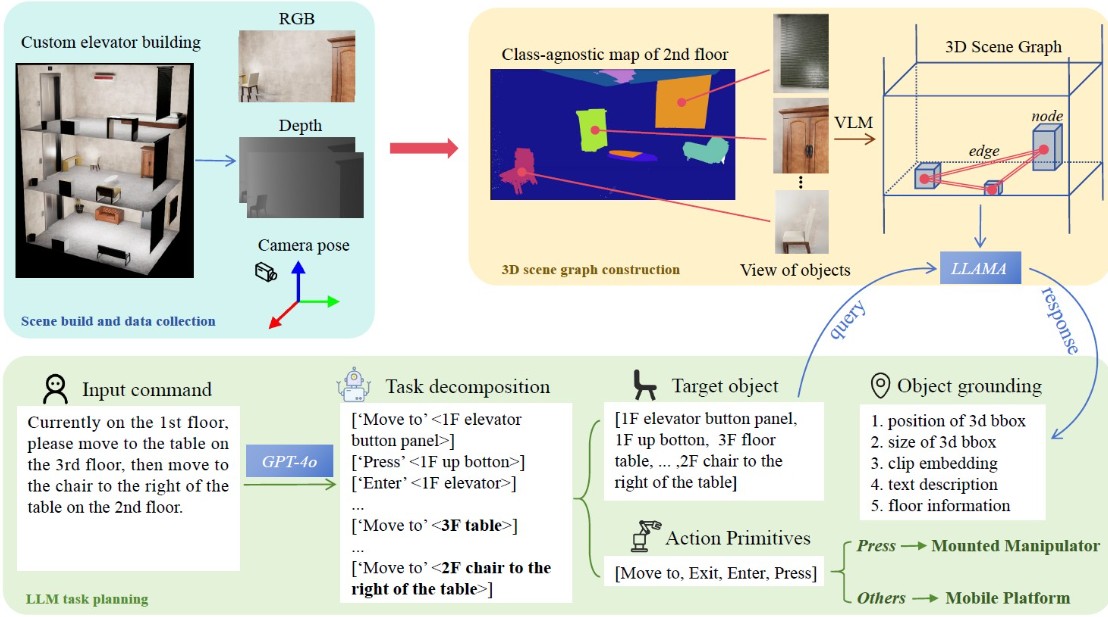
Рисунок 2. Схема обработки информации в системе LaMDEN. Система строит семантическую карту окружения (в центре), после чего большая языковая модель (на схеме — GPT-4) получает от пользователя сложную задачу (слева) и разбивает ее на простые команды-примитивы (например, «нажать кнопку» или «войти в лифт»), которые робот может последовательно выполнить. Источник: IJCNN Proceedings
Для проверки своей системы ученые создали реалистичную виртуальную среду в симуляторе Isaac Sim — своего рода цифровой двойник трехэтажного здания с полностью функциональным интерактивным лифтом. В этом симуляторе, который можно сравнить с продвинутым полигоном для роботов, в качестве агента выступала модель мобильного манипулятора Mobile ALOHA.
Эксперименты показали высокую эффективность предложенного подхода. Система, использующая граф сцены в сочетании с дополнительными алгоритмами компьютерного зрения для точного распознавания кнопок, достигла 80% успеха в выполнении ключевой операции — нажатия нужной кнопки. Это значительный скачок по сравнению с более простыми методами, где успешность не превышала 10–40%. Исследователи также сравнили работу различных языковых моделей и выяснили, что новейшие версии, такие как GPT-4o, справляются с задачей планирования значительно лучше своих предшественников.

Рисунок 3. Ключевые «примитивы действия», освоенные роботом. Слева показано, как манипулятор выполняет действие «нажать кнопку», взаимодействуя с панелью лифта. Справа — примеры навигационных действий мобильной платформы: «войти», «выйти» и «двигаться к целевому объекту». Источник: IJCNN Proceedings
Дмитрий Юдин, завлабораторией интеллектуального транспорта ЦКМ МФТИ, рассказал об этой работе:
«Новый подход основан на объединении двух технологий. Построение графа 3D-сцены дает роботу способность детально понимать окружающее пространство, а применение большой языковой модели в связке с оригинальным эвристическим алгоритмом планирования траектории позволяет роботу эффективно рассуждать и планировать свои действия в этом пространстве.
Именно это сочетание восприятия и когнитивного планирования позволило приблизиться к решению такой сложной задачи, как взаимодействие с лифтом. Это приближает нас к созданию роботов, которые смогут действовать не в искусственных лабораторных условиях, а в реальных пространствах».
Коллектив планирует усовершенствовать свою систему, чтобы она могла работать в динамичных средах. Следующим вызовом станет научить робота взаимодействовать с лифтом не в одиночку, а в присутствии людей и других движущихся объектов, например, уступая дорогу или ожидая своей очереди.
Научная статья (LaMDEN): Huzhenyu Zhang and Dmitry Yudin;«LaMDEN: Addressing Elevator-Based Navigation with Large Language Models and 3D Scene Graphs», 2025 International Joint Conference on Neural Networks (IJCNN), Rome, Italy, 2025, pp. 1-8; DOI: 10.1109/IJCNN64981.2025.11228224.
Научная статья (ElevNav): Huzhenyu Zhang; «ElevNav: Large Language Model-Guided Robot Navigation via 3D Scene Graphs in Elevator Environments»; Opt. Mem. Neural Networks 34, 313–322 (2025); DOI: https://doi.org/10.3103/S1060992X25700109.
Публикуем набор данных, собранных для построения графов сцен, который станет ценным дополнением к текущему исследованию. Код и наборы данных доступны с открытым исходным кодом по адресам:
- https://github.com/zhanghuzhenyu/mul-floor-navigation — проект LaMDEN;
- https://github.com/zhanghuzhenyu/elevnav — проект ElevNav, используется для реконструкции 3D-графов сцен.
